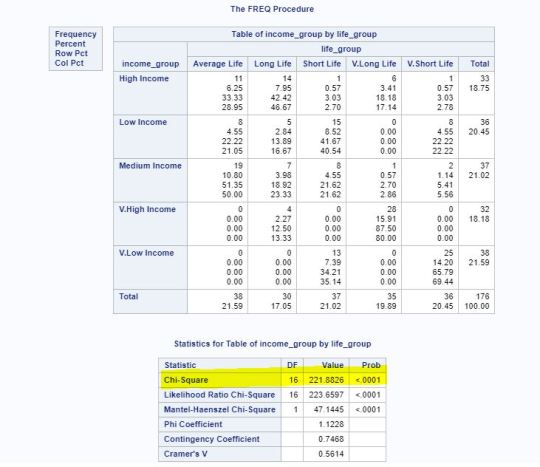
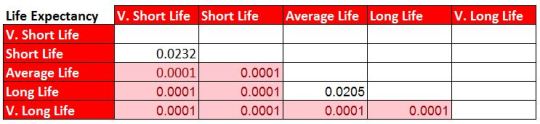
Data analysis tools occupy a position rarified atop the data ecosystem, converting data into a story. What they really do is make meaning. They don’t just compute numbers or render charts. They decide what gets counted, how it’s grouped, what’s visible, what’s comparable, and what’s ignored. Those decisions shape how people understand reality inside an organization. In that sense, analytics isn’t downstream of meaning — it’s one of the primary ways meaning is constructed.

For example, an analytics dashboard doesn’t merely report revenue. It asserts a story about how revenue should be understood: what time frame matters, which segments are relevant, what constitutes success or failure. A funnel chart doesn’t just show drop-off; it implies causality, priority, and responsibility. Someone is now accountable for that slope.
Analytics platforms are meaning-making machines because they:
- Select: Out of infinite possible measurements, a platform surfaces a few.
- Frame: Through dimensions, filters, and time windows, it defines context.
- Stabilize: It freezes interpretations into reusable metrics (“this is what churn means here”).
- Authorize: Numbers displayed on an “official” dashboard carry institutional weight.
- Normalize: Over time, repeated views become assumed truths rather than hypotheses.
That’s why disagreements over dashboards feel political rather than technical. People aren’t arguing about SQL — they’re arguing about which interpretation of reality gets to be the default. And this is also why analytics platforms differ so dramatically in philosophy.
Take Looker’s insistence on a semantic layer, for example. It isn’t just about governance — it’s about centralizing meaning. It says: interpretation should be controlled, hierarchal, deliberate, and versioned. Tableau’s emphasis on free exploration, on the other hand, reflects a different belief: meaning should emerge through visual interaction and human intuition. Sigma’s spreadsheet model leans on familiarity, letting people reason in a language they already trust. Power BI’s tight integration with Excel acknowledges that meaning often forms outside formal BI systems — in ad-hoc models and side calculations. None of these are neutral choices.
Even seemingly mundane design decisions carry interpretive weight. Does the platform default to month-over-month or year-over-year? Does it make cumulative metrics easy and cohort analysis hard? Does it encourage slicing by geography or by customer segment? Each of these nudges how people think, not just what they see. And this extends beyond platforms to analysis itself.
Analysis is not the act of discovering objective truth hidden in data. It’s the act of constructing a plausible narrative from incomplete, biased, and historically contingent signals. The math matters, but the story matters more — because the story is what gets acted on.
This is why “self-service BI” is such a complicated phrase. What’s really being democratized isn’t access to data; it’s access to interpretation. And interpretation without shared context can fragment meaning instead of clarifying it. That’s why analytics maturity often follows a curve: exploration first, then chaos, then governance, then—if you’re lucky—shared understanding.

It also explains why analytics tools so often disappoint when organizations expect them to “settle debates.” They don’t. They formalize them. Once a metric is codified in a dashboard, the argument shifts from “what happened?” to “why does this number say that?” and eventually to “should this number even exist?”
In that sense, data analysis tools are more like a language than a machine. They provide grammar (models, metrics, dimensions), vocabulary (fields, measures), and syntax (charts, dashboards). Different tools encourage different dialects. Over time, organizations develop an accent — a way of speaking about performance, risk, and success that feels natural but is entirely constructed.
So in the end, data analysis tools help create the reality an organization believes it’s operating in. And that’s why choosing one is never a purely technical decision. It’s a choice about how meaning gets made, shared, and enforced inside the system.
What are data analysis tools actually used for?
Most organizations use data analytics tools for four overlapping jobs.
The first is exploration. Analysts and power users need a place to poke at data, slice it different ways, test hypotheses, and follow threads without writing a new query for every idea. This is where filters, drill-downs, joins, and ad-hoc calculations live. A good data analysis tool makes exploration feel playful. A bad one turns curiosity into work.
The second is dashboards and operational visibility. These are the shared views—the revenue board, the funnel chart, the SLA dashboard—that become the organization’s ambient awareness. They’re consulted daily, sometimes obsessively. When they’re right, teams become focused on shared goals. When they’re wrong, entire weeks can be wasted arguing over whose numbers are “correct.”
The third is reporting and distribution. Scheduled reports, embedded analytics, board decks, regulatory summaries—analytics platforms are the engine behind all of them. This is where permissions, formatting, and delivery reliability start to matter as much as query performance.
The fourth—and often the most underestimated—is semantic modeling and governance. This is where analytics platforms either shine or slowly poison trust. If “revenue,” “active user,” or “conversion” mean different things in different dashboards, the platform is failing, no matter how pretty the charts look.
What Makes One Data Analysis Tool Better Than Others?
The difference between a good analytics tool and death by a thousand cuts isn’t about beautiful, easy-to-read charts or a quick and slick dashboard. It’s about whether the tool survives contact with actual organizations, and the flawed humans they’re made of. A good data analysis tool - like any data tool - must be able to deftly compensate for the irrationalities, inefficiencies, and absurdities that we humans are made of.
Our gift for irrationality requires a tool that insists on rigorous data governance. Platforms that allow (or require) metrics to be defined once and reused everywhere will dramatically reduce confusion and rework. Platforms that shunt this responsibility onto individual dashboard authors will allow metric drift that, over time, confidence erodes in the rules and definitions that are the meat of the analysis. You’ll have your pretty charts but they’ll be illustratin’ doo-doo. You’ll think it’s chocolate milk but it’s watered-down Yoohoo. I’m talkin:
- Can you define metrics once and reuse them everywhere?
- Row-level security, object permissions, audit logs, lineage-ish capabilities.
Similarly, our many very human inefficiencies make how the tool performs at scale - and especially concurrency - a second criterium that makes or breaks a good data analysis tool. A platform that works beautifully for one analyst can collapse when hundreds of people open dashboards at once. How it pushes compute - for example some tools lean heavily on in-memory engines, while others push computation down into the warehouse, and still others blend caching strategies, makes a big difference when scaled to enterprise. These architectural choices show up very quickly in real usage, especially on Monday mornings.
Usability does to our myriad human absurdities what good parents do for a family - define norms with a gentle touch In my experience, and what I hear in conversations with other developers, is that the best platforms are so elegantly opinionated that you find it . They guide users toward sane patterns and discourage destructive ones. A tool that lets everyone do everything often ends up doing nothing well.
Extensibility also matters a lot to people trying to apply data anlytics to a product, a portal, or an internal tool . Many organizations want analytics embedded in products, portals, or internal tools. That requires APIs, embedding controls, tenant isolation, and pricing models that don’t punish success.
Finally, there’s total cost of ownership. License (or usage) price is only part of the story. Training time, admin overhead, duplicated datasets, broken dashboards, and governance cleanup all cost real money—even if they don’t show up on an invoice.
The Chase
Ok smart guy, you say. If it all boils down to firm but gentle governance, stability at scale, simplicity, extensability, and cost, then let’s cut to the chase - which data analysis tool has all five in spades? Ah, would that it were such a sweet simplicity that the best data analysis tool is the merely the tool that checks all five boxes in that list? I wish.
Instead, what you find is something like a tension graph, where each quality pulls against one or more of the others. I’ve had this conversation so many times with various developers, informally polling to get the lay of the data analytics land, with the same handful of questions and the handful of names turning up again and again, that I knew this was both a question in need of an answer, and an answer that was in desperate need of further analysis.
If you’d like to read me making sweet meaning out of the field of data analysis tools, as well as lay your cones and rods upon a data visualization so sensual it will touch you right in your soul (or therabouts), then for god’s sake click here to read my piece on the best data analysis tools.
Data Analysis Tool FAQs
Which data analysis tool should I choose?
It depends on your stack and users. Power BI works well in Microsoft environments, Tableau is strong for visualization, Looker for governed modeling, and Sigma for warehouse-native analysis. The “best” tool is the one that fits your data sources, budget, and team skills.
Do we really need a data warehouse first?For serious analytics, yes. Running reports directly on application databases doesn’t scale. A warehouse like Snowflake, BigQuery, or Redshift provides performance, separation from production systems, and a central place for clean, modeled data.
What’s the difference between BI tools and analytics tools?BI tools focus on dashboards and reporting. Analytics tools can include data preparation, modeling, statistics, and exploration. Many modern analytics platforms blend both capabilities.
Extract-based or live-query tools—what should we use?Extracts are fast but require extra pipelines. Live-query tools simplify architecture but rely on warehouse performance. Choose based on data size, freshness needs, and infrastructure costs.
How do I integrate analytics into my application?Most platforms offer APIs and embedding options so dashboards can live inside your product with single sign-on and programmatic access controls.
How important is the semantic layer?It’s crucial. A strong semantic layer ensures metrics are defined once and used consistently, preventing conflicting reports and duplicated SQL logic.
What’s the biggest risk when adopting a data tool?Poor data quality and governance. The tool matters less than having clean, modeled, and trusted data feeding it. See my article about data cleaning before visualization to learn more.