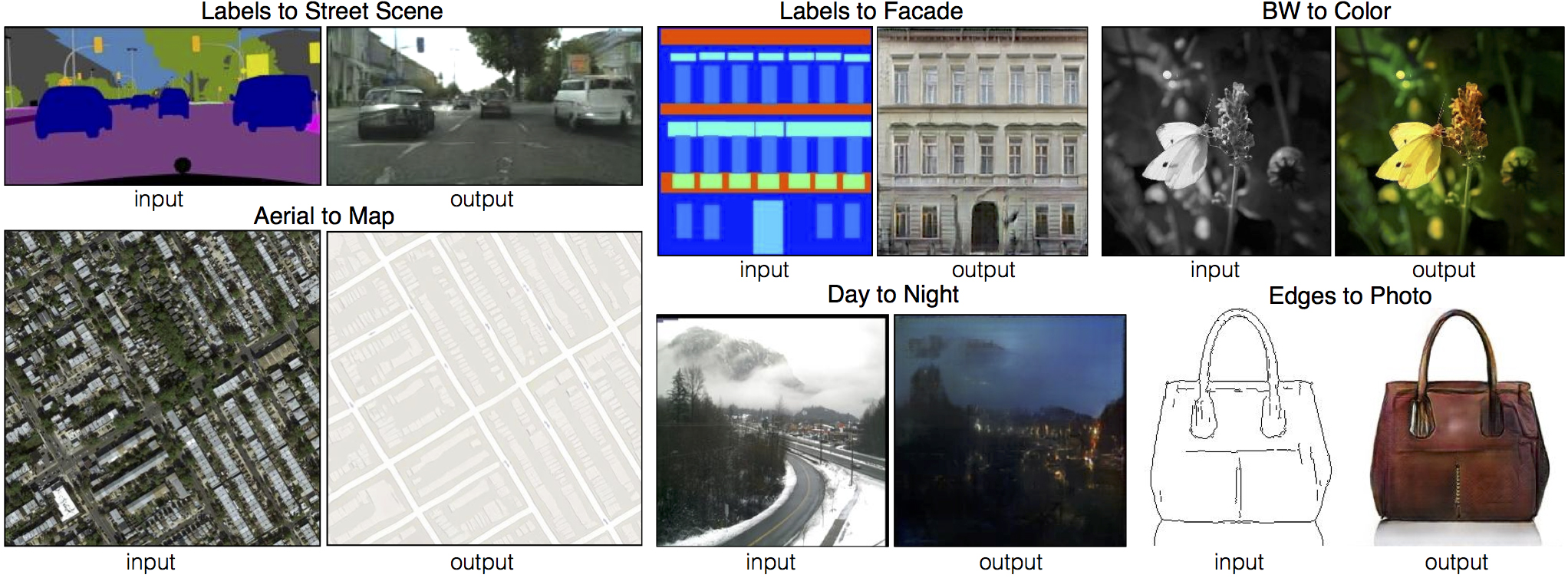
Computer Vision at CVPR 2024 with Qualcomm AI research

CVPR 2024 workshops
Qualcomm Technologies is excited to present five research papers on the main track, 11 on co-located workshops, 10 demos, two co-organized workshops, and other research community events at the Computer Vision and Pattern Recognition Conference (CVPR) 2024 on Monday, June 17. CVPR honors’ the greatest research and previews the future of generative artificial intelligence (AI) for photos and videos, XR, automotive, computational photography, robotic vision, and more with a 25% acceptance rate.
At top conferences like CVPR, meticulously peer-reviewed papers establish the new state of the art (SOTA) and contribute to the community. Qualcomm Technologies has accepted several papers in generative AI and perception that advance computer vision research.
Generative AI research
Text-to-image diffusion models enable fast, high-definition visual content creation at high computational expense. The paper “Clockwork UNets for Efficient Diffusion Models” introduces Clockwork Diffusion to improve model efficiency. They use computationally intensive UNet-based denoising in every generation. However, the paper notes that not all operations affect output quality equally.
High-resolution feature maps make UNet layers sensitive to slight perturbations, while low-resolution maps have less effect. Based on this fact, Clockwork Diffusion proposes periodically reusing computation from previous denoising steps to approximate low-resolution feature maps.
Reducing FLOPs by 32% improves Stable Diffusion v1.5 perceptual scores. The approach works on low-power edge devices, making it scalable for real-world applications. Clockwork is covered in this blog post on efficient generative AI for photos and videos.
CVPR papers
Solving optical flow estimation data scarcity
Qualcomm study “OCAI: Improving Optical Flow Estimation by Occlusion and Consistency Aware Interpolation” proposes a novel method named OCAI to handle data scarcity in optical flow estimation:
- Generates intermediate video frames and optical fluxes for robust frame interpolation.
- Uses occlusion-aware forward-warping to resolve pixel value discrepancies and fill missing values.
This research also introduces a teacher-student semi-supervised learning strategy that trains a student model using interpolated frames and flows, boosting optical flow accuracy. The benchmarks show that OCAI has perceptually better interpolation and optical flow accuracy.
Better optical flow accuracy can improve robot navigation, car movement detection, and more.
Enhancing depth completion accuracy
With their article “DeCoTR: Enhancing Depth Completion with 2D and 3D Attentions,” Qualcomm AI Research accomplished state-of-the-art depth completion for computer vision. The research proposes combining 2D and 3D attentions to improve depth completion accuracy without repetitive spatial propagations. Look for 2D features in bottleneck and skip connections:
- The baseline convolutional depth completion model is improved to match sophisticated transformer-based models.
- The authors elevate 2D features to generate a 3D point cloud and process it with a 3D point transformer to let the model explicitly learn and utilise 3D geometric features.
DeCoTR shows superior generalizability over current techniques by setting new SOTA performance on depth completion benchmarks. This has potential applications in autonomous driving, robotics, and augmented reality, where depth estimation is critical.
Enhancing stereo video compression
New multimodal technologies like virtual reality and autonomous driving have boosted need for efficient multi-view video compression.
Existing stereo video compression methods sequentially compress left and right views, limiting parallelization and runtime efficiency. Low-Latency Neural Stereo Streaming (LLSS) is a new parallel stereo video coding technology. This is addressed by LLSS:
- A new bidirectional feature shifting module uses mutual information to encode views effectively using a joint cross-view prior model for entropy coding.
- LLSS may process left and right images simultaneously, reducing latency and increasing rate-distortion performance over neural and conventional codecs.
The approach saves 15.8% to 50.6% bitrates on benchmark datasets, outperforming SOTA.
Allowing natural facial expressions
With so many AI-generated faces and characters, facial expressions and transfers must be more natural. This affects gaming and content. Facial action unit (AU) intensity quantifies fine-grained expression behaviours, making it ideal for facial expression modulation. In “AUEditNet: Dual-Branch Facial Action Unit Intensity Manipulation with Implicit Disentanglement,” the scientists accurately manipulated AU intensity in high-resolution synthetic facial images.
- AUEditNet, trained with 18 individuals, manipulates intensity across 12 AUs well.
- Qualcomm use a dual branch architecture to separate facial characteristics and identification without loss functions or high batch sizes.
- Conditioning modification on intensity values or target images without retraining the network or adding estimators is possible with AUEditNet.
This process for facial attribute modification shows promise despite the dataset’s small subject count.
Displays of technology
Qualcomm demonstrate their generative AI and computer vision research in real life to prove its practicality. Visit booth #1931 to try these technologies. Here are some demos to showcase.
Generative AI
Stable Diffusion with LoRA adapters on Android smartphones is shown on generative AI. Personal or creative preferences can be used to create high-quality Stable Diffusion photos with LoRA adapters. Users might choose a LoRA adaptor and set its strength to get the desired image.
Android phone multimodal LLM is also shown. Qualcomm present Large Language and Vision Assistant (LLaVA), a more than 7 billion-parameter LMM that can produce multi-turn conversations about images using text and photographs. Reference design enabled by Snapdragon 8 Gen 3 mobile platform operated LLaVA on smartphone at a responsive token rate.
Computer vision
Other interesting computer vision demonstrations are at booth:
- Improved real-time and precise segmentation on edge devices: This technology can segment known and unknown classes in photos and videos using user inputs like touch, drawing a box, or inputting text.
- Generational video portrait relighting technology: Works with generative AI for background replacement to improve video chat facial realism.
- AI helper on device: Uses an audio-driven 3D avatar with lip-syncing and expressive face motions to engage users.
Qualcomm also demonstrate a cutting-edge face performance capture and retargeting system that can capture complex facial expressions and transform them onto digital avatars, making digital interactions more realistic and personalised.
Autonomous vehicle technology or AV technology
Qualcomm’s Snapdragon Ride sophisticated driver-assistance system demos perception, mapping, fusion, and vehicle control using their modular stack approach for automotive applications. Qualcomm showcase includes driver monitoring system improvements and generative AI-augmented camera sensor data for model training in challenging settings.
Collaborative workshops
- Efficient Large Vision Models (eLVM): Many computer vision jobs now use efficient large vision models (eLVM). Qualcomm AI Research is co-organizing the Efficient Large Vision Models Workshop to increase LVM accessibility to researchers and practitioners by focusing on computing efficiency. Exploring concepts for effective LVM adaptation to downstream tasks and domains without rigorous model training and fine-tuning empowers the community to do research with limited computational budget. Accelerating LVM inference allows them to be used in real-time applications on low-computing platforms like cars and phones.
- Omnidirectional Computer Vision (OmniCV): A wide field of vision makes omnidirectional cameras popular in automotive, security, photography, and augmented/virtual reality. To connect omnidirectional vision research and practice, Qualcomm AI Research is co-organizing the Omnidirectional Computer Vision Workshop. This session bridges formative research backing these achievements to commercial products using this technology. It promotes novel imaging modality methods and applications that will advance the field.
Join us in advancing generative AI and computer vision
This is just a sampling of Qualcomm’s CVPR 2024 highlights. Come to Qualcomm booth #1931 to learn about their research, see their demos, and discuss AI careers.
Read more on Govindhtech.com