Cluster computing, cloud computing, and grid computing are different approaches used to combine the power of multiple computers to perform tasks more efficiently. Cluster computing connects several computers in the same location so they can work together as a single system. Cloud computing provides computing resources such as servers, storage, and applications over the internet whenever they are needed. Grid computing links computers from different locations to share resources and solve large and complex problems. In simple terms, clusters function as one powerful unit, clouds deliver services online, and grids combine distributed resources to handle large-scale computing tasks.
A new distributed computing platform from Queensland University of Technology and other experts addresses huge data processing’s tough All-to-All Comparison Problems. The new method provides 88% of optimal performance in multi-machine situations. This should accelerate data mining, bioinformatics, and biometrics applications.
A “new distributed computing framework” reduced the goal value for optimising quantum circuit execution by 88.40% that day. These breakthroughs show rapid high-performance and distributed computing progress.
Revolutionizing Big Data Analysis
Resolving All-to-All Comparison
Due to their exponential development, processing massive data sets requires a lot of compute and storage in a short time. These problems often use the All-to-All Comparison Problem, which compares all files in a data set. This comparison is needed in data mining, biometrics, and bioinformatics (CVTree issue). Since these concerns are intrinsic, worker nodes must communicate extensively, which increases storage usage and may cause load imbalances.
Creative data distribution and load balancing
New system relies on high-performance computing embedded data delivery technology. This method aims to:
Pre-distributing files to worker nodes minimises storage usage.
Distribute comparison jobs efficiently to maximise worker node processing power.
In systems with limited bandwidth, preserving good data locally allows all comparison operations to be conducted without data transfers or connections between worker nodes during computation.
In a test with 256 files and varied numbers of storage nodes, this strategy significantly reduced storage space compared to approaches that distribute all data to every node.
Becoming Effective
Close to Ideal To prove this strategy works, trials were done on a homogenous Linux cluster. With more processors, the framework accelerated linearly, demonstrating strong scalability.
Despite network connections, memory, and disc access costs in All-to-All comparison tasks, the computing framework reached 88% of the optimal linear speed-up’s performance capacity. To verify this, the CVTree issue, a bioinformatics All-to-All Comparison issue, was reprogrammed to use the framework’s APIs.
Beyond traditional solutions such as Hadoop
The researchers noted that Hadoop and other big data processing frameworks often fail to solve All-to-All Comparison Problems. The MapReduce processing pattern’s inability to match the All-to-All pattern causes load imbalances and poor data locality in Hadoop’s data distribution mechanism.
However, data localisation, load balancing, and storage savings give the new method significant performance advantages over Hadoop-based alternatives. Hadoop-based Strategy II’s data locality compromise to save space caused thousands of operations requiring data movement and communication.
Future work for this approach includes adapting the data distribution method to heterogeneous distributed computing systems, including dynamic job scheduling, and testing large-scale distributed computing systems.
Advancements in Computing Quantum Computing: From Molecular Switches to Circuit Optimisation Beyond big data, quantum computing is advancing rapidly. Quantum News announced on August 22, 2025, that Autocom, a novel distributed computing architecture, optimised quantum circuit execution on distributed quantum computers and reduced goal value by 88.40%. This framework addresses key quantum processing unit mapping and communication concerns. The development of molecular switches for stable one-state model learning was also noteworthy.
A model that can process time-varying inputs steadily justifies the employment of solvable molecular switch models as computational units in deep learning architectures for neuromorphic computing. Another quantum development was the construction of a matter-wave interferometer to research quantum gravity and a novel key distribution technique.
Data Management, Hardware, and AI Advances Throughout computer science, many advances occurred:
New methods like TurboMind mixed-precision LLM inference reduce the memory and computing needs of Large Language Models (LLMs). They achieve 156% better throughput and 61% lower serving latency than earlier frameworks.
RISC-V microkernel support speeds up GenAI workloads and quantised neural networks for microcontrollers make deep neural networks on embedded systems possible.
Data Pipeline Architectures: A novel Declarative Data Pipeline design increases development efficiency by 50% and performance by 500x for large-scale machine learning applications managing billions of records. Homomorphism Calculus for User-Defined Aggregations implements user-defined aggregating functions well in Apache Spark.
AI for Health: Researchers suggested Structure-Aware Temporal Modelling to predict chronic diseases, including Parkinson’s, and XAI-Driven Spectral Analysis of Cough Sounds to characterise respiratory disorders.
Hardware, distributed computing, quantum technology, and artificial intelligence (AI) advancements highlight a creative period that is boosting computer capacity for crucial scientific and commercial needs.
Project Title: ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning - Scikit-Learn-Exercise-001.
Project Title:
ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning
File Name:
global_fraud_detection_pipeline.py
This project implements an ultra-advanced fraud detection system that integrates heterogeneous data sources, graph-based feature extraction, and ensemble meta-learning. The pipeline combines robust preprocessing (missing…
Project Title: ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning - Scikit-Learn-Exercise-001.
Project Title:
ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning
File Name:
global_fraud_detection_pipeline.py
This project implements an ultra-advanced fraud detection system that integrates heterogeneous data sources, graph-based feature extraction, and ensemble meta-learning. The pipeline combines robust preprocessing (missing…
Project Title: ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning - Scikit-Learn-Exercise-001.
Project Title:
ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning
File Name:
global_fraud_detection_pipeline.py
This project implements an ultra-advanced fraud detection system that integrates heterogeneous data sources, graph-based feature extraction, and ensemble meta-learning. The pipeline combines robust preprocessing (missing…
Project Title: ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning - Scikit-Learn-Exercise-001.
Project Title:
ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning
File Name:
global_fraud_detection_pipeline.py
This project implements an ultra-advanced fraud detection system that integrates heterogeneous data sources, graph-based feature extraction, and ensemble meta-learning. The pipeline combines robust preprocessing (missing…
Project Title: ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning - Scikit-Learn-Exercise-001.
Project Title:
ai-ml-ds-SrmZNuoOhMk – Global Fraud Detection and Prevention Pipeline with Hybrid Graph and Ensemble Learning
File Name:
global_fraud_detection_pipeline.py
This project implements an ultra-advanced fraud detection system that integrates heterogeneous data sources, graph-based feature extraction, and ensemble meta-learning. The pipeline combines robust preprocessing (missing…
💡 Did you know? 📊 The rise of big data has led to the development of technologies like Apache Hadoop 🐘 and Spark 🔥, which can process vast amounts of data quickly across distributed systems 🌐💻. . . 👉For more information, please visit our website: https://zoofinc.com/ ➡Your Success Story Begins Here. Let’s Grow Your Business with us! 👉Do not forget to share with someone whom it is needed.
➡️Let us know your opinion in the comment below 👉Follow Zoof Software Solutions for more information ✓ Feel free to ask any query at info@zoof.co.in ✓ For more detail visit: https://zoof.co.in/ . . .
In today’s data-driven world, machine learning has become an essential tool for many industries. However, traditional machine learning approaches often require large amounts of centralized data, which can pose a risk to privacy and security. Federated learning is an innovative approach to machine learning that allows for collaborative model training without the need to centralize data. In this article, we will explore what federated learning is, how it works, and its potential benefits and challenges.
Federated Learning for Data Privacy
Federated learning is a machine learning approach that enables multiple devices or servers to collaboratively train a model without sharing raw data. This approach is particularly useful in situations where data privacy is a concern, as it allows for the distributed training of a model without the need to centralize data. In federated learning, each device locally trains a model on its own data and sends only the updated model parameters to a centralized server. The server then aggregates these updates from multiple devices to create an improved model, which is then sent back to each device for further training.
One of the primary benefits of federated learning is data privacy. With traditional machine learning approaches, data needs to be centralized in order to train a model, which can pose a risk to privacy and security. With federated learning, data remains on the local devices and is not shared, which reduces the risk of data breaches and other privacy violations. This is particularly important in industries such as healthcare and finance, where data privacy is of utmost importance.
Federated learning also has potential benefits for efficiency and scalability. With traditional machine learning approaches, large amounts of data need to be centralized and processed on a single server, which can be time-consuming and resource-intensive. Federated learning distributes the computation across multiple devices, making it possible to train models on large-scale datasets without the need for a centralized infrastructure. This can result in significant time and cost savings.
However, there are also some challenges associated with federated learning. One of the main challenges is ensuring that the local models are accurate and representative of the overall dataset. Since each device only trains on its own data, it is important to ensure that the local models are not biased towards certain types of data or users. This can be addressed through techniques such as stratified sampling and weighted averaging.
Another challenge is ensuring that the model updates sent by each device are secure and reliable. Since these updates are sent over a network, they are vulnerable to attacks such as eavesdropping and tampering. This can be addressed through techniques such as secure aggregation and encryption.
Federated learning offers a promising approach to privacy-preserving machine learning. As this technology continues to evolve, it is likely that we will see an increasing number of applications in various industries, and it will be important for both researchers and industry professionals to continue to explore its potential benefits and limitations.
Architectures
There are several types of federated learning architecture, including Federated Averaging, Federated Stochastic Gradient Descent, Split Learning, Hybrid Federated Learning, and Collaborative Learning. Each architecture has its own unique features and advantages, making it more suitable for specific types of datasets and applications. Understanding the different federated learning architectures is important for developing efficient and effective machine learning models that can be trained on decentralized data without compromising data privacy or security.
Federated Averaging
Federated Averaging is a popular federated learning algorithm for training machine learning models on decentralized data. In Federated Averaging, the training process is distributed across multiple devices, and the model is updated through a process of aggregation and averaging.
The Federated Averaging algorithm works as follows:
- A central server distributes the initial model to a set of client devices.
- Each client device trains the model locally on its own data, using a stochastic gradient descent algorithm.
- After each local training iteration, the client device computes a model update and sends it back to the central server.
- The central server aggregates the model updates received from the client devices, by taking a weighted average of the updates.
- The central server then computes a new model using the aggregated update, and sends it back to the client devices for further training.
- The process is repeated for a set number of rounds or until a convergence criteria is met.
-
The key advantage of Federated Averaging is that it allows the training of a machine learning model on decentralized data, without the need to centralize the data in one location. This is particularly important when dealing with sensitive or private data, as it allows the data to remain on the client devices and be protected by the clients themselves. Additionally, the Federated Averaging algorithm has been shown to be efficient and effective, particularly for large-scale datasets.
Federated Stochastic Gradient Descent
Federated Stochastic Gradient Descent (FSGD) is a type of federated learning algorithm that enables the training of machine learning models on decentralized data, without the need to centralize the data in one location. In FSGD, each device or node in a decentralized network computes a gradient of the model on its own local data, and sends the gradient to a central server, which aggregates the gradients and updates the model.
The FSGD algorithm works as follows:
- A central server distributes the initial model to a set of client devices.
- Each client device computes a gradient of the model on its own local data, using a stochastic gradient descent algorithm.
- The client device sends the gradient to the central server.
- The central server aggregates the gradients received from the client devices, by taking the average of the gradients.
- The central server updates the model using the aggregated gradient, and sends the updated model back to the client devices.
- The process is repeated for a set number of rounds or until a convergence criteria is met.
FSGD is particularly useful when dealing with large-scale datasets or when the client devices have limited computing resources or bandwidth. It allows the model to be trained on decentralized data while still being updated centrally, which can help improve the efficiency of the training process. Additionally, FSGD can provide better privacy guarantees than other federated learning algorithms, as the client devices do not need to share their local data with the central server.
Split Learning
Split Learning is a type of federated learning algorithm that allows the training of machine learning models on decentralized data, without the need to transfer the data to a central server for processing. Instead, in Split Learning, a portion of the model is stored on a client device, while the rest of the model is stored on a central server. The client device trains its portion of the model on its own data and sends the results to the central server, which aggregates the results and updates the central portion of the model.
The Split Learning algorithm works as follows:
- A central server distributes a partially trained model to a set of client devices.
- Each client device trains its portion of the model on its own local data, using the partial model as a starting point.
- The client device sends the results of its local training to the central server.
- The central server aggregates the results received from the client devices, by taking the average of the results.
- The central server updates the central portion of the model using the aggregated results, and sends the updated model back to the client devices.
- The process is repeated for a set number of rounds or until a convergence criteria is met.
Split Learning is particularly useful when dealing with highly sensitive or private data, where it is important to keep the data on the client devices and protect the privacy of the data. Additionally, Split Learning can be more efficient than other federated learning algorithms, as it reduces the amount of data that needs to be transferred between the client devices and the central server.
Hybrid Federated Learning
Hybrid Federated Learning is a type of federated learning algorithm that combines elements of both Federated Averaging and Split Learning. In Hybrid Federated Learning, some layers of the model are stored on the client devices, while other layers are stored on the central server. The client devices train their layers on their own local data and send the results to the central server, which aggregates the results and updates the central layers of the model.
The Hybrid Federated Learning algorithm works as follows:
- A central server distributes a partially trained model to a set of client devices.
- Each client device trains its portion of the model on its own local data, using the local layers and the partially trained model as starting points.
- The client device sends the results of its local training to the central server.
- The central server aggregates the results received from the client devices, by taking the average of the results.
- The central server updates the central layers of the model using the aggregated results, and sends the updated model back to the client devices.
- The process is repeated for a set number of rounds or until a convergence criteria is met.
Hybrid Federated Learning is particularly useful when dealing with datasets that have both structured and unstructured data, or when different layers of the model require different amounts of processing power. By storing some layers on the client devices and others on the central server, Hybrid Federated Learning can help optimize the training process and improve the efficiency of the algorithm.
Collaborative Learning
Collaborative Learning is a type of federated learning algorithm that enables multiple clients to work together to train a shared machine learning model. In Collaborative Learning, the clients exchange information and collaborate to improve the model, which is then updated centrally.
The Collaborative Learning algorithm works as follows:
- A central server distributes an initial model to a set of client devices.
- Each client device trains the model locally on its own data and sends the results of its training to the other client devices.
- The client devices exchange information and collaborate to improve the model, using techniques such as model averaging, model ensembling, and transfer learning.
- The client devices then send the updated model to the central server.
- The central server aggregates the updated models and computes a new model, which is sent back to the client devices for further training.
- The process is repeated for a set number of rounds or until a convergence criteria is met.
Collaborative Learning is particularly useful when dealing with datasets that have diverse characteristics, or when the client devices have different computing resources or processing power. By allowing multiple clients to work together to train a shared model, Collaborative Learning can help improve the accuracy and robustness of the model, while also reducing the amount of time and resources required for training.
Conclusion
Federated learning is an innovative machine learning approach that offers a way to train models collaboratively without the need to centralize data. While it offers many benefits, including improved data privacy and efficiency, it also comes with its own set of challenges. As this technology continues to evolve, it is important for both researchers and industry professionals to be aware of its potential benefits and limitations.
Hey Fellow Kids: Meta Is Revamping Horizon Worlds to Attract More Teen Users
Nothing has been more of a spectacle to watch than Meta’s bet on the metaverse—more specifically Horizon Worlds, a virtual reality video game platform from the company. It appears Meta isn’t ready to give up on Horizon Worlds just yet, as internal documents from the company reveal a revamping strategy of the platform… Read more…
What Happens When China Makes a Popular Homegrown Movie Disappear?
What Happens When China Makes a Popular Homegrown Movie Disappear?
Return to Dust, a movie that had been generating buzz in China as a sleeper hit, was unceremoniously pulled from streaming services in the country yesterday, according to multiple reports on social media. Mentioning the film on Weibo, China’s equivalent to Twitter, has even been banned. Will movie fans outside China… Read more…
How to Save Money by ‘Churning’ Your Streaming Services
How to Save Money by ‘Churning’ Your Streaming Services
Like most people, you probably subscribe to so many (too many) streaming services—and yet, each one carries a show you’d hate to miss. With price hikes across the board, the cost of keeping up with all your favorite shows and films is getting out of hand, but none of us are going back to traditional cable TV. If you… Read more…
Using boinc again to crunch numbers to fight COVID. I use Rosetta as well but it’s currently not working on a project but will be again soon. It just was a couple of days ago. #boinc #worldcommunitygrid #covidvacccine #covi̇d19 #distributedcomputing (at North Ogden, Utah) https://www.instagram.com/p/CaIFliGuPJU/?utm_medium=tumblr
Folding@home e’ un progetto di calcolo distribuito per simulare la dinamica delle proteine - il processo di piegatura delle proteine e i movimenti delle proteine implicati in una varieta’ di tumori e malattie, tra cui l'Alzheimer, l'Ebola e il COVID-19.
Consentendo alle persone di tutto il mondo di eseguire queste simulazioni sui propri personal computer, il progetto Folding@home mira ad aiutare gli scienziati a comprendere meglio questi processi e identificare nuove opportunità di trattamenti.Ovviamente, puoi eseguire Folding@home come macchina virtuale anche nel Cloud della Secure Online Desktop. Il client Folding@home è disponibile nei template delle macchine virtuali, quindi tutti gli utenti del Cloud Server possono usarlo per costruire la propria macchina virtuale. Ecco una guida rapida per configurarlo.
1. Costruisci un virtual server utilizzando il template Folding@home
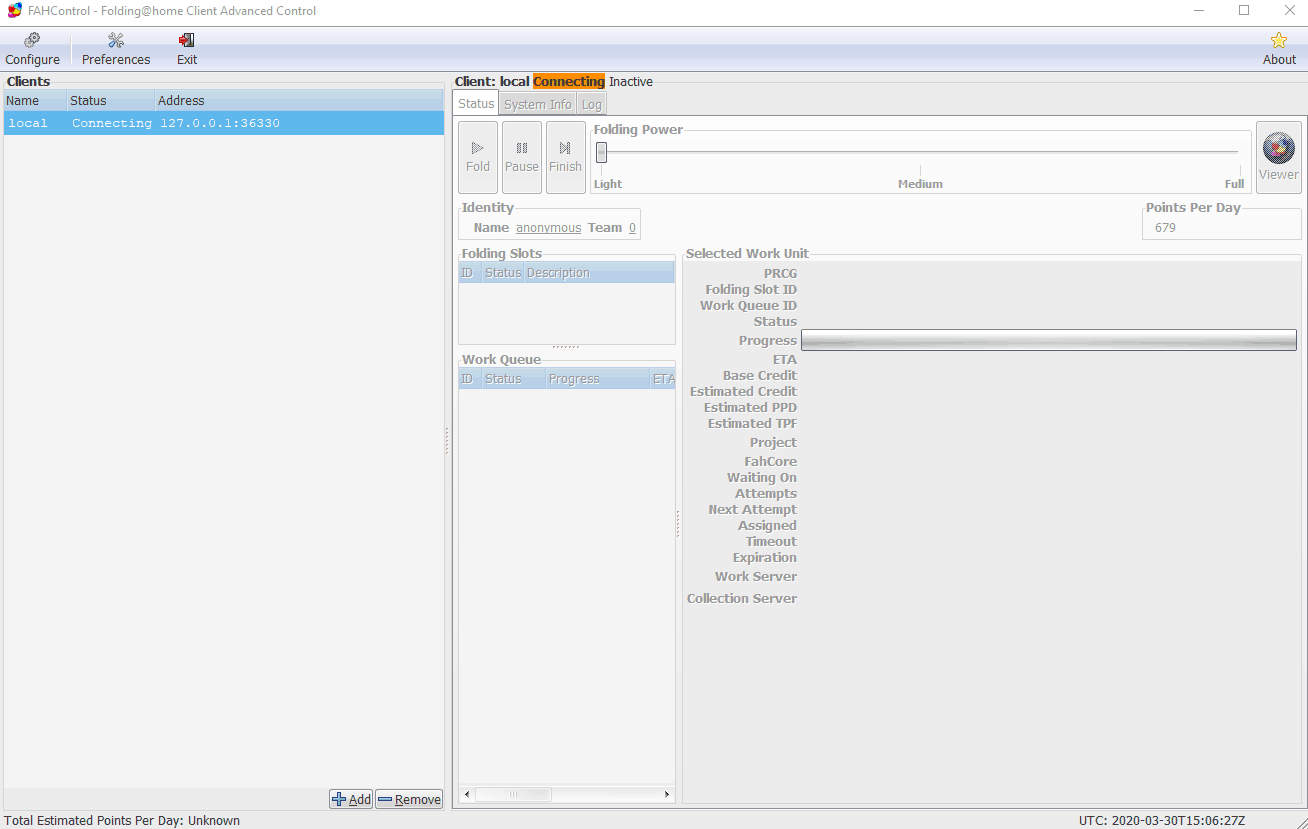
Per iniziare, effettua il deploy di un server virtuale utilizzando questo modello: CentOS 7.7 x64 FoldingHome. Modifica CPU/RAM a tuo piacimento e crea il VS.Una volta che il Virtual Server (VS) è attivo e in esecuzione, ssh/console su VS e confermare che il servizio fah è in esecuzione: # /etc/init.d/FAHClient status fahclient is running with PID 1268Modifica config.xml nella directory /etc/fahclient e modificalo per aggiungere la sezione , in cui possiamo dire al client il nostro indirizzo IP remoto. Oppure fai come ho fatto in questo caso e consenti l'accesso da tutti (0.0.0.0/0) ma con una password:# cat /etc/fahclient/config.xml A questo punto, con la configurazione sopra aggiunta, riavvia il servizio fah: # /etc/init.d/FAHClient restart Stopping fahclient … OK Starting fahclient … OK
2. Installare FAHControl
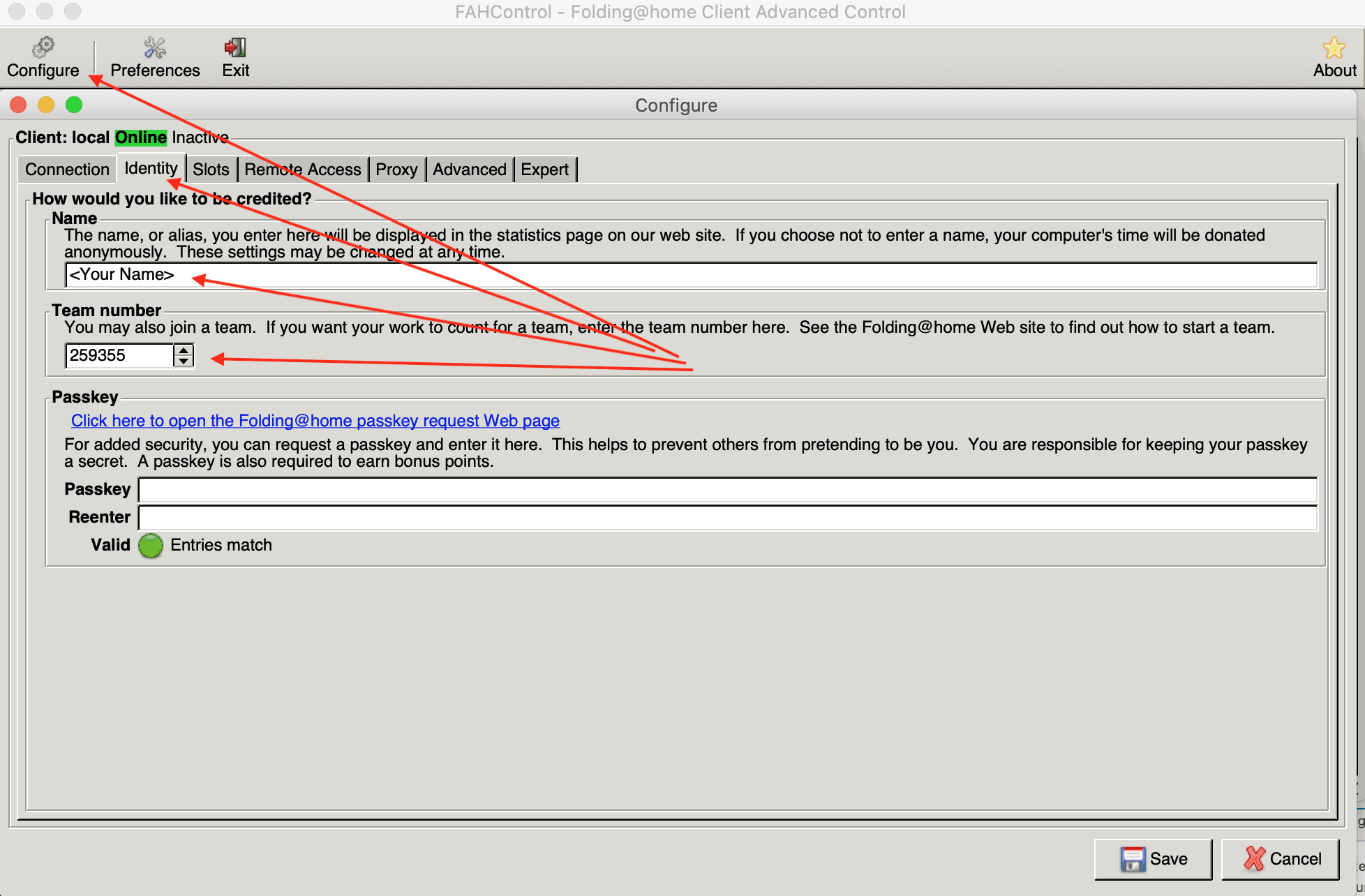
Successivamente installeremo FAHControl sul PC desktop o laptop locale. È una GUI per il controllo di uno o più client Folding@home. Puoi saperne di più e ottenere l'installer da https://foldingathome.org/support/faq/installation-guides/Una volta installato, avvia l'applicazione e dovresti vedere qualcosa di simile a questo: Ora possiamo aggiungere il nostro client in esecuzione sul VS implementato su Secure Online Desktop. Sarà necessario l'indirizzo IP pubblico del VS e verificare di poter raggiungere la porta 36330.Fare clic sul piccolo pulsante Aggiungi nella parte inferiore del client FAHControl e fornire il nome visualizzato, il nome host/indirizzo IP e la password impostati in precedenza.Nella sezione Configure, nella scheda Identity specifica il tuo nome e il nostro numero di Team che è 259355 come riportato di seguito:Ora dovresti vedere che FAHControl è connesso e funziona.Per maggiori dettagli su come funziona e altre informazioni sul progetto Folding@home, visitare il sito https://foldingathome.org/.Infine puoi controllare le statistiche del nostro team qui: https://stats.foldingathome.org/team/259355 incluso il tuo contributo.Vi preghiamo di notare che per aiutare il progetto Folding@home non è obbligatorio creare un VPS sul nostro Cloud, è possibile utilizzare anche il proprio PC per farlo. Il vantaggio di supportare il progetto Folding@home tramite il nostro VPS è che, diversamente dal tuo PC, puoi lasciare il processo sempre attivo e, ad esempio, puoi allocare risorse libere (come CPU e RAM) che hai incluso nel tuo abbonamento Cloud Server o SuperCloud . Link utili:Cloud serversDatacenter in ItalyownCloud free for Corona Virus (COVID-19) emergencyVirtual serverWindows Demo Server | Remote desktop accessPublic Cloud Reggio EmiliaAzienda Contattaci
30% CPU cycles on all 8 cores works great! I’m churning out data like crazy! #boinc #distributedcomputing #ibmworldcommunitygrid #worldcommunitygrid #universeathome #rosettaathome it just cycles thru my three projects like crazy. I’ll see, twice, Rosetta@home at .1% and then suddenly the next day it’s gone, completed. That’s fast for overnight charging because it runs when I’m not using my phone and it’s charging, only. (at North Ogden, Utah) https://www.instagram.com/p/CNzycBphaWZ/?igshid=1xpn39lbhkfb8
In using all 8 cores, my BOINC went to town! I’m very pleased! And i set the CPU percentage to 30% so it isn’t even warm! And I’m backing up video to my photo album at the same time! Those tweaks are important for it to properly crunch numbers. #boinc #distributedcomputing #rosettaathome #ibmworldcommunitygrid #worldcommunitygrid #covid19relief #covid_19 #covid #coronaviruspandemic #covi̇d19 I’m seriously pleased as punch. The task list was way way different before with Rosetta at .1% with two or three tasks so overnight it finished them! Twice! (at North Ogden, Utah) https://www.instagram.com/p/CNrwqx9B7i-/?igshid=ei77r10s2uqd
Folding@home e’ un progetto di calcolo distribuito per simulare la dinamica delle proteine - il processo di piegatura delle proteine e i movimenti delle proteine implicati in una varieta’ di tumori e malattie, tra cui l'Alzheimer, l'Ebola e il COVID-19.
Consentendo alle persone di tutto il mondo di eseguire queste simulazioni sui propri personal computer, il progetto Folding@home mira ad aiutare gli scienziati a comprendere meglio questi processi e identificare nuove opportunità di trattamenti.
Ovviamente, puoi eseguire Folding@home come macchina virtuale anche nel Cloud della Secure Online Desktop. Il client Folding@home è disponibile nei template delle macchine virtuali, quindi tutti gli utenti del Cloud Server possono usarlo per costruire la propria macchina virtuale. Ecco una guida rapida per configurarlo.
1. Costruisci un virtual server utilizzando il template Folding@home
Per iniziare, effettua il deploy di un server virtuale utilizzando questo modello: CentOS 7.7 x64 FoldingHome. Modifica CPU/RAM a tuo piacimento e crea il VS.
Una volta che il Virtual Server (VS) è attivo e in esecuzione, ssh/console su VS e confermare che il servizio fah è in esecuzione:
# /etc/init.d/FAHClient status fahclient is running with PID 1268
Modifica config.xml nella directory /etc/fahclient e modificalo per aggiungere la sezione , in cui possiamo dire al client il nostro indirizzo IP remoto.